Today we launched a new look for OpenNMS, a rebranding effort that has been going on for the better part of a year. It represents a lot more than just a new logo and new colors. While OpenNMS has been around for over two decades now, it is also quite different from when it started. A tremendous amount of work has gone into the project over the past couple of years, and if you looked at using it even just a short while ago you will be surprised at what has changed.
![]()
One of the best analogies I can come up with to talk about the “new” OpenNMS concerns cars. I like cars, especially Mercedes, and when I was in college I usually drove an older Mercedes sedan. I enjoyed bringing them back to their former glory (and old, somewhat beaten down cars were all I could afford), and so I might start by redoing the brake system, overhauling the engine, etc.
When I would run out of money, which was often, sometimes I’d have to sell a car. Prospective buyers would often complain that the paint wasn’t perfect or there was an issue with the interior. I’d point out that you could hop in this car right now and drive it across the country and never worry about breaking down, but they seemed focused on how it looked. Cosmetics are usually the last thing you focus on during a restoration, but it tends to be the first thing people see.
This is very much like OpenNMS. For over a decade we’ve been focused on the internals of the platform, and luckily we are now in a position to focus on how it looks.
Please don’t misunderstand: application usability is important, much more important than, say, the paint job on a car, but in order to provide the best user experience we had to start by working under the hood.
For example, from the beginning OpenNMS has contained multiple “daemons” that control various aspects of the platform. Originally this was very monolithic, and thus any small change to one of them would often require restarting the whole application.
OpenNMS is now based on a Karaf runtime which provides a modular way of managing the various features within the application. It comes with a shell that can allow even non-Java programmers access to both high and low level parts of the platform, and to make changes without restarting the whole thing. Features can be enabled and disabled on the fly, and it is easy to test the behavior of OpenNMS against a particular device without having to set up a special test environment to pore through pages of logs.
Another great aspect of OpenNMS is that much of the internal messaging can now take place through a broker such as Kafka. While this increases the stability and flexibility of the platform, users can also create custom consumers for the huge amounts of information OpenNMS is able to collect. For very large networks this creates the option to use that data outside of the platform itself, giving end users a high level of custom observablity.
The monolithic nature of OpenNMS has also been improved. The addition of “Minions” to provide monitoring at the edge of the network creates numerous monitoring solutions where there was none before. You can now reach into isolated or private networks, or monitor the performance of applications from various locations seamlessly. The “Sentinel” project allows the various processes within OpenNMS to be spread out over multiple devices with the aim to have virtually unlimited scale.
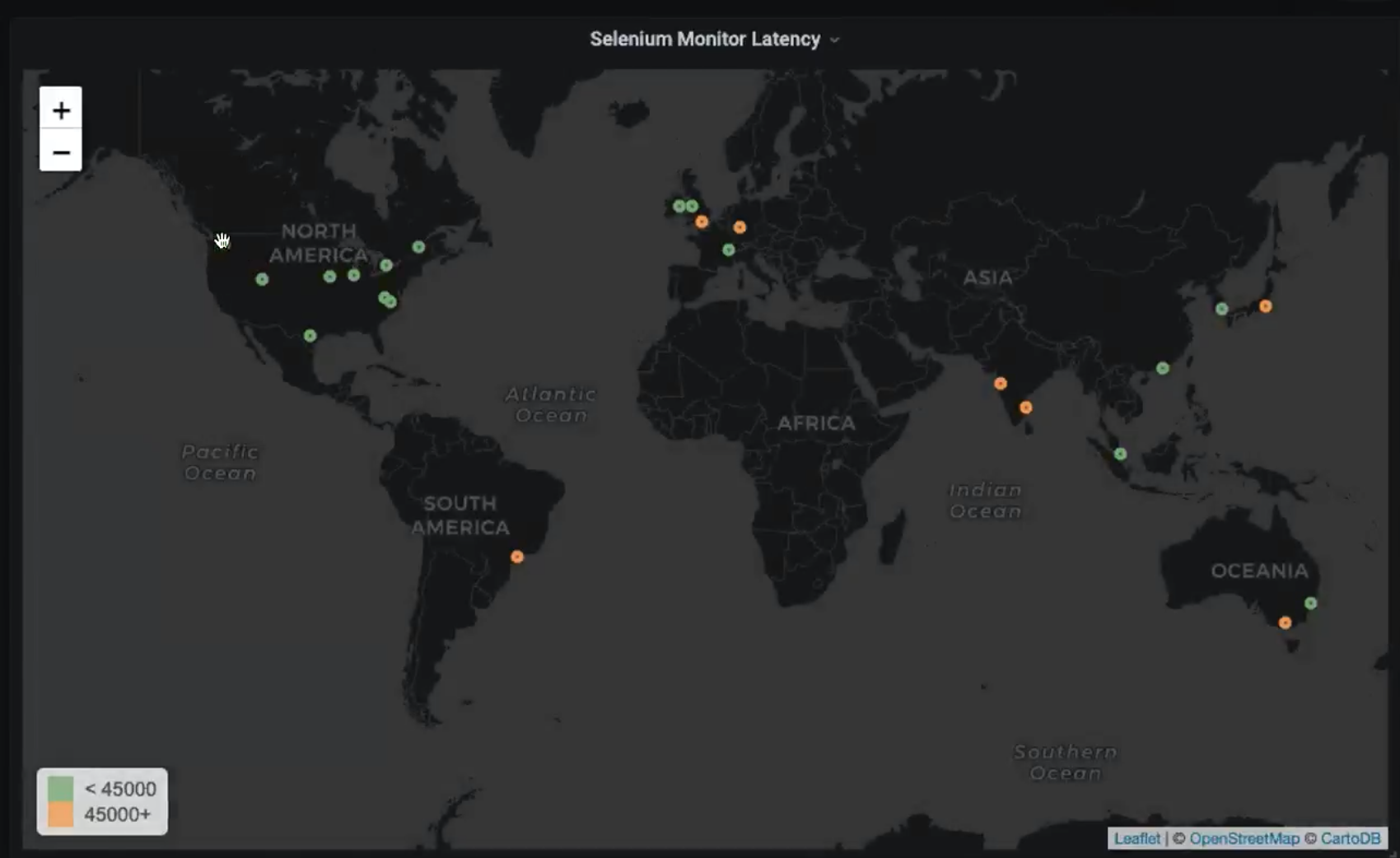
And I haven’t even started on the ability of OpenNMS to monitor tremendous amounts of telemetry data and to analyze it with tools such as “Nephron” or our foray into artificial intelligence with ALEC.
So much has changed with OpenNMS, much of it recently, that it was time for that new coat of paint. It was time for people to both notice the new look of OpenNMS at the surface, and the new OpenNMS under the covers.
One thing that hasn’t changed is that OpenNMS is still 100% open source. All of these amazing features are available to anyone under an OSI approved open source license. Plus we leverage and integrate with best-in-class open source tools such as Grafana for visualization and Cassandra (using Newts) for storing time series data.
Our new logo is a stylized gyroscope. For centuries the gyroscope has represented a way to maintain orientation in the most chaotic of situations. In much the same way, OpenNMS helps you maintain the orientation of your IT infrastructure which, let’s admit it, plays a huge role in the success of your enterprise.
Where the car analogy falls apart is that while the paint job is usually the end of a restoration, this new look for OpenNMS is just the beginning of a new chapter in the history of the project. Our goal is to create a platform where monitoring just happens. We’re not there yet, but check out the latest OpenNMS and we hope you’ll agree we are getting closer.