Rant
PSA
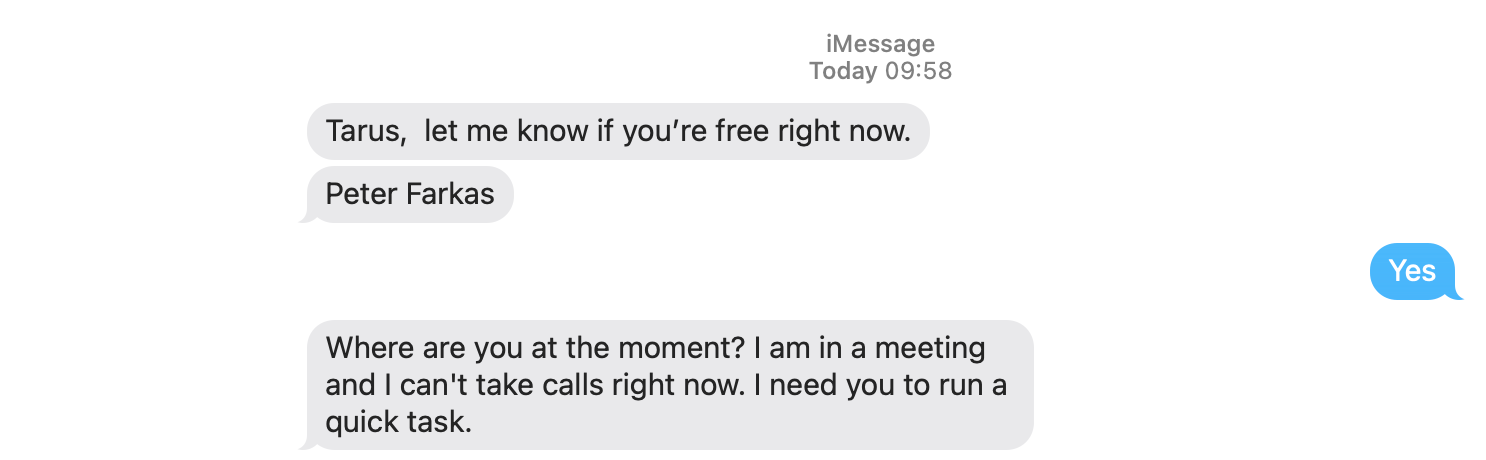
I Got Scammed
Open Source
Percona
Day One at Percona
Open Source
Stuff
Internet of Things
Sonoff Zigbee Bridge with Home Assistant
Open Source
Conferences
San Francisco Omnistrate Event
AWS
Farewell AWS
Commentary
Travel
The Grand Hyatt Gets an AI Agent
AWS
Amazon Web Services - Four Years and Out
Commentary
Open Source
Revisiting Trademarks
Conferences
GrafanaCon 2026
Open Source
Commentary
Revisiting Email
1
2
3
4
122
Jump to page
(1 - 122)
Go
Enter
Press Enter to jump