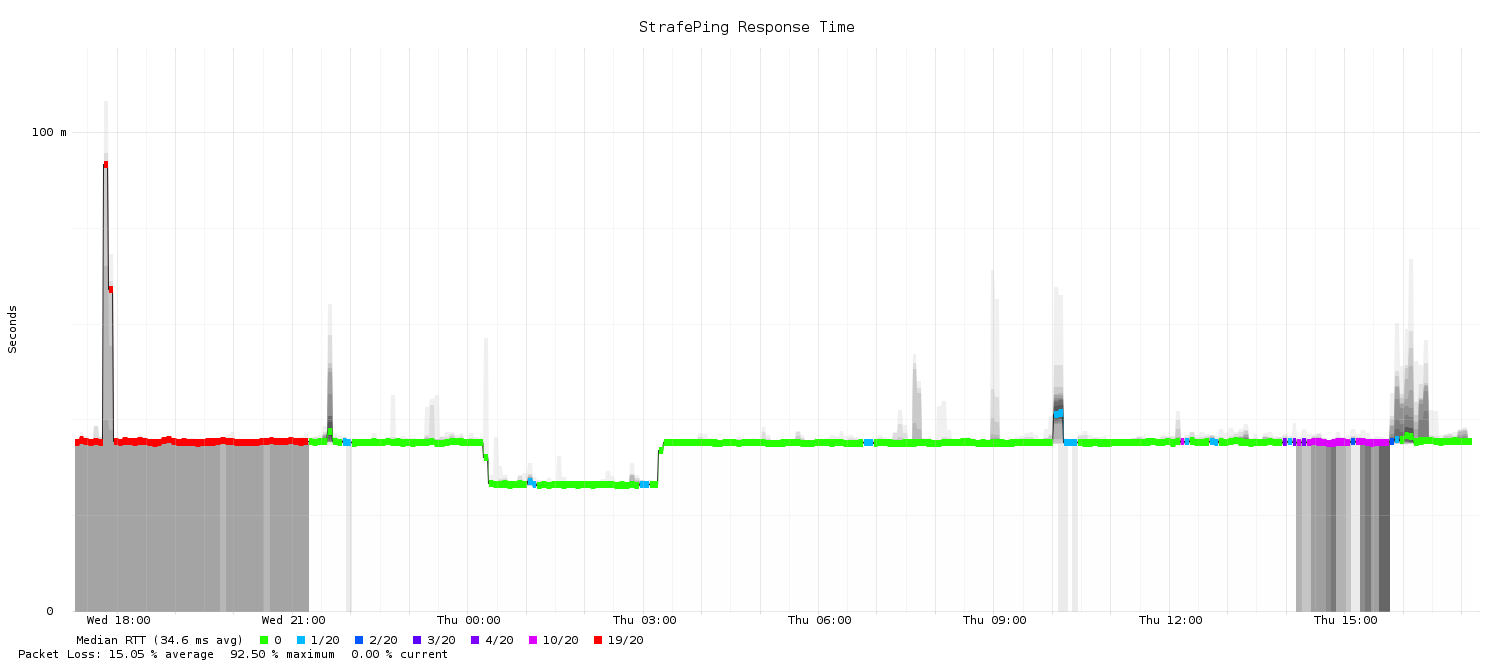
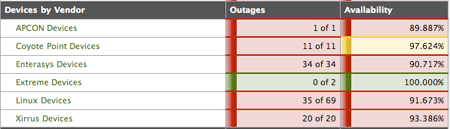
To most people, monitoring is not exciting, but it seems lately that the most exciting thing in monitoring is the Prometheus project. As a project endorsed by the Cloud Native Computing Foundation, Prometheus is getting a lot of attention, especially in the realm of cloud applications and things like monitoring Kubernetes.
At this year’s Open Source Monitoring Conference they offered a one day training course, so I decided to take it to see what all the fuss was about. I apologize in advance that a lot of this post will be comparing Prometheus to OpenNMS, but in case you haven’t guessed I’m biased (and a bit jealous of all the attention Prometheus is getting).
The class was taught by Julien Pivotto who is both a Prometheus user and a decent instructor. The environment consisted of 15 students with laptops set up on a private network to give us something to monitor.
Prometheus is written in Go (I’m never sure if I should call it “Go” or if I need to say “Golang”) which makes it compact and fast. We installed it on our systems by downloading a tarball and simply executing the application.
Like most applications written in the last decade, the user interface is accessed via a browser. The first thing you notice is that the UI is incredibly minimal. At OpenNMS we get a lot of criticism of our UI, but the Prometheus interface is one step above the Google home page. The main use of the web page is for querying collected metrics, and a lot of the configuration is done by editing YAML files from the command line.
Once Prometheus was installed and running, the first thing we looked at was monitoring Prometheus itself. There is no real magic here. Metrics are exposed via a web page that simply lists the variables available and their values. The application will collect all of the values it finds and store them in a time series database called simply the TSDB.
The idea of exposing metrics on a web page is not new. Over a decade ago we at OpenNMS were approached by a company that wanted us to help them create an SNMP agent for their application. We asked them why they needed SNMP and found they just wanted to expose various metrics about their app to monitor its performance. Since it ran on Linux system with an embedded web server, we suggested that they just write the values to a file, put that in the webroot, and we would use the HTTP Collector to retrieve and store them.
The main difference between that method and Prometheus is that the latter expects the data to be presented in a particular format, whereas the OpenNMS method was more free-form. Prometheus will also collect all values presented without extra configuration, whereas you’ll need to define the values of interest within OpenNMS.
In Prometheus there is no real auto-discovery of devices. You edit a file in which you create a “job”, in our case the job was called “Prometheus”, and then you add “targets” based on IP address and port. As we learned in the class, for each different source of metrics there is usually a custom port. Prometheus stats are on port 9100, node data is exposed on 9090 via the node_exporter, etc. When there is an issue, this can be reflected in the status of the job. For example, if we added all 15 Prometheus instances to the job “Prometheus” and one of them went down, then the job itself would show as degraded.
After we got Prometheus running, we installed Grafana to make it easier to display the metrics that Prometheus was capturing. This is a common practice these days and a good move since more and more people are becoming familiar it. OpenNMS was the first third-party datasource created for Grafana, and the Helm application brings bidirectional functionality for managing OpenNMS alarms and displaying collected data.
After that we explored various “components” for Prometheus. While a number of applications are exposing their data in a format that Prometheus can consume, there are also other components that can be installed, such as the node_exporter which displays server-related metrics and to provide data that isn’t otherwise natively available.
The rest of the class was spent extending the application and playing with various use cases. You can “alertmanager” to trigger various actions based on the status of metrics within the system.
One thing I wish we could have covered was the “push” aspect of Prometheus. Modern monitoring is moving from a “pull” model (i.e. SNMP) to a “push” model where applications simply stream data into the monitoring system. OpenNMS supports this type of monitoring through the telemetryd feature, and it would be interesting to see if we could become a sink for the Prometheus push format.
Overall I enjoyed the class but I fail to see what all the fuss is about. It’s nice that developers are exposing their data via specially formatted web pages, but OpenNMS has had the ability to collect data from web pages for over a decade, and I’m eager to see if I can get the XML/JSON collector to work with the native format of Prometheus. Please don’t hate on me if you really like Prometheus – it is 100% open source and if it works for you then great – but for something to manage your entire network (including physical servers and especially networking equipment like routers and switches) you will probably need to use something else.
[Note: Julien reached out to me and asked that I mention the SNMP_Exporter which is how Prometheus gathers data from devices like routers and switches. It works well for them and they are actively using it.]