It has been awhile since we had an entry into the Order of the Blue Polo, so I thought it would be cool to blog about it.
While the Order of the Green Polo (OGP) is the governing body of the OpenNMS Project, we wanted to find a way to recognize users who didn’t quite have the time necessary to dedicate to the project for OGP membership. It also solves a problem for us: we have lots of amazing users of OpenNMS, but we can’t always talk about them.
Membership in the Order of the Blue Polo is pretty straightforward. Simply send us an e-mail on why you like OpenNMS, preferably with a quick list of the number of devices/interfaces/services you are monitoring. If we can publish it on the wiki along with your name and your company’s name, we’ll send you a limited edition blue OpenNMS polo. So please, no gmail.com or yahoo.com e-mails – we really need to be able to verify your company.
This helps us because like attracts like, and perhaps someone will read about how you are using OpenNMS and decide that it fits in with their needs.
The latest entry into the Order comes from Paul Cole, a contractor and Environment Canada. He writes:
I am a contractor working currently for Environment Canada (under Shared services Canada).
It was a beautiful thing to be given the OpenNMS project in order to map out and bring together teams to monitor and work on the very large LAN. A multitude of tools and scripts were used custom to each area, and we are now moving towards unification.
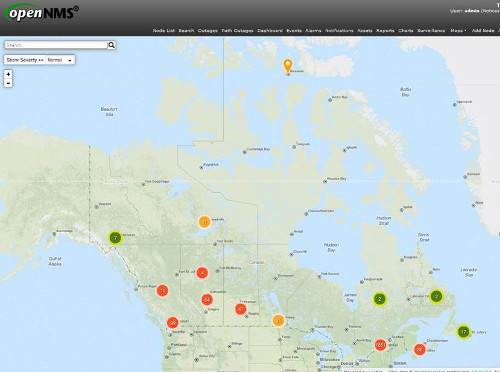
The visibility and baseline abilities of OpenNMS are fantastic, and the new topo-mapping/geo-mapping features are looking fantastic come version 1.14!
Our network size is larger than the current scope of nodes we are testing with, but OpenNMS is managing it pretty smoothly and seamlessly.
I have released some of the scripts I wrote to contribute back to the community that are based on version 1.10-1.12 and hope they help more people realise the power and scalability of the product.
Currently our OpenNMS build is monitoring over 15k nodes and 20k interfaces and 25k or more services (exact numbers can be extracted but it grows every quarter), on an 8 core server with 16GB of RAM using the discovery method.
It is keyed to discover every IP and node it can, and monitor switches/UPSs and routers and select key devices for management, to send email alerts to the appropriate regional teams when a device is down or a specific threshold or alert is received.
I can’t of course send out network diagrams , but I can send a screenshot of the geo-map to give an idea of how it goes.