A few months ago, Anna Widenius, the CEO of the MariaDB Foundation, reached out to me about hosting a meetup in London to discuss database performance. AWS, my employer, has offices in most major cities, so I decided to use her request to learn how to navigate the process for requesting a room, and I managed to reserve a space in the AWS LHR16 building in the Shoreditch area of London.
I have been traveling a lot this year and couldn’t justify a trip to London for just this event, so I reached out to my friend Ricardo for help. He put me in touch with another Amazonian named Azam, and with their help I was able to get the event sorted out.
As luck would have it, I did end up needing to come to London for a meeting scheduled for the following Monday, so I was happy to come in a few days early to make the event (and I plan to stay for the AWS Summit London).

Anna wasn’t able to make the trip but Monty Widenius did and he acted as the master of ceremonies. We had around 80 people sign up and about half of them actually came to the meeting (grin). The format was to have four 45 minute presentations followed by some pizza and networking.

After Monty did the introductions, the first speaker was Steve Shaw. He is the developer of HammerDB, an open source database benchmarking application.
The first thing he discussed was the DeWitt Clause. Computer scientist David DeWitt did a database benchmarking study in 1982 that demonstrated that the Oracle database had poor performance under the tested loads. In response, Oracle added a clause to its end user agreement that prohibited users from disclosing the results of such tests. I knew of that limitation in the Oracle users agreement but didn’t know it had a name or its history.
Of course, this sent me down a rabbit hole researching the DeWitt Clause where I came across a variant called the DeWitt Embrace Clause. This allows third parties to publish benchmarks under the stipulation that they will provide enough detail to allow the test to be replicated, and if the third party has a similar product the first party can benchmark it and publish the results. For example, if Oracle wanted to benchmark a competitive database licensed with a DeWitt Embrace Clause they would need to also allow the benchmark to be run against their products and the results published.
Shaw then went on to discuss how HammerDB worked and the different types of tests. While standards in database performance measurement were traditionally set by the Transaction Processing Performance Council (TPC), their benchmarking methods are not open source, so HammerDB uses similar but not identical tests. One (TPROC-C) measures raw transactional load while another (TPROC-H) simulates a more in-depth load, such as someone placing an order on a website where the process will consist of multiple transactions.
At the end of the presentation Shaw talked about causes of performance bottlenecks, and in many cases it comes down to hardware. My old open source project spent a lot of time tuning PostgreSQL performance, and often that meant separating the application, logs and database onto different disks (yes, this was pretty much pre-cloud). Some examples that were presented in the talk involved servers with multiple physical CPUs, but with the network cards inserted into slots whose interrupts were only handled by one of them, causing contention. In another example he talked about the scaling_governor kernel parameter that can be set to a number of values, such as powersave versus performance (the laptop I am using to write this is set to schedutil).
While the main use case discussed for HammerDB is for comparing different database solutions, I would use it to measure how various configuration changes impact performance on a given database. It can be difficult to determine if a particular change was positive or not.

The next speaker was Ori Weizman, representing Silk.
I’m going to try to be nice about this, but Weizman’s talk was too sales focused for the forum. He presented a first-call sales pitch deck and not a technical talk. He admitted that he was a sales person and if he could leave our meeting with one or two possible partner leads it would make the trip worthwhile. It really bothered me. For one slide he replaced “SQL Server” with “MariaDB” live during the talk.
Many open source projects today are backed by a company with a commercial component, but in open source forums the focus is on open source and not paid offerings. It is possible to blur the line a bit (see the RDS talk below) but I would have liked it if the talk could have been more focused on open source value.
From what I can gather, Silk provides a cloud-based storage solution for databases that has better performance and costs less than other options. In the interest of full disclosure, Silk does not run on AWS and at least one person I talked to enjoyed the presentation, so take my comments with that in context, but many people came up to me after the event and expressed displeasure at being shown a sales pitch.

The third presentation was given by Alex Hanshaw of MariaDB plc. He went over the work that has been done over the last year to add vector index capabilities to the database.
The talk had basically two parts: the first part described vectors and how this feature worked and the second discussed the performance of the feature.
His example of vectors was one of the best I’ve seen. He created a collection of four, two dimensional vectors. The dimensions were “size” and “speed”. Remember that most AI/ML vectors have hundred if not thousands of dimensions, but his oversimplification was useful. He populated his database with four examples (which would represent the training portion of a model):
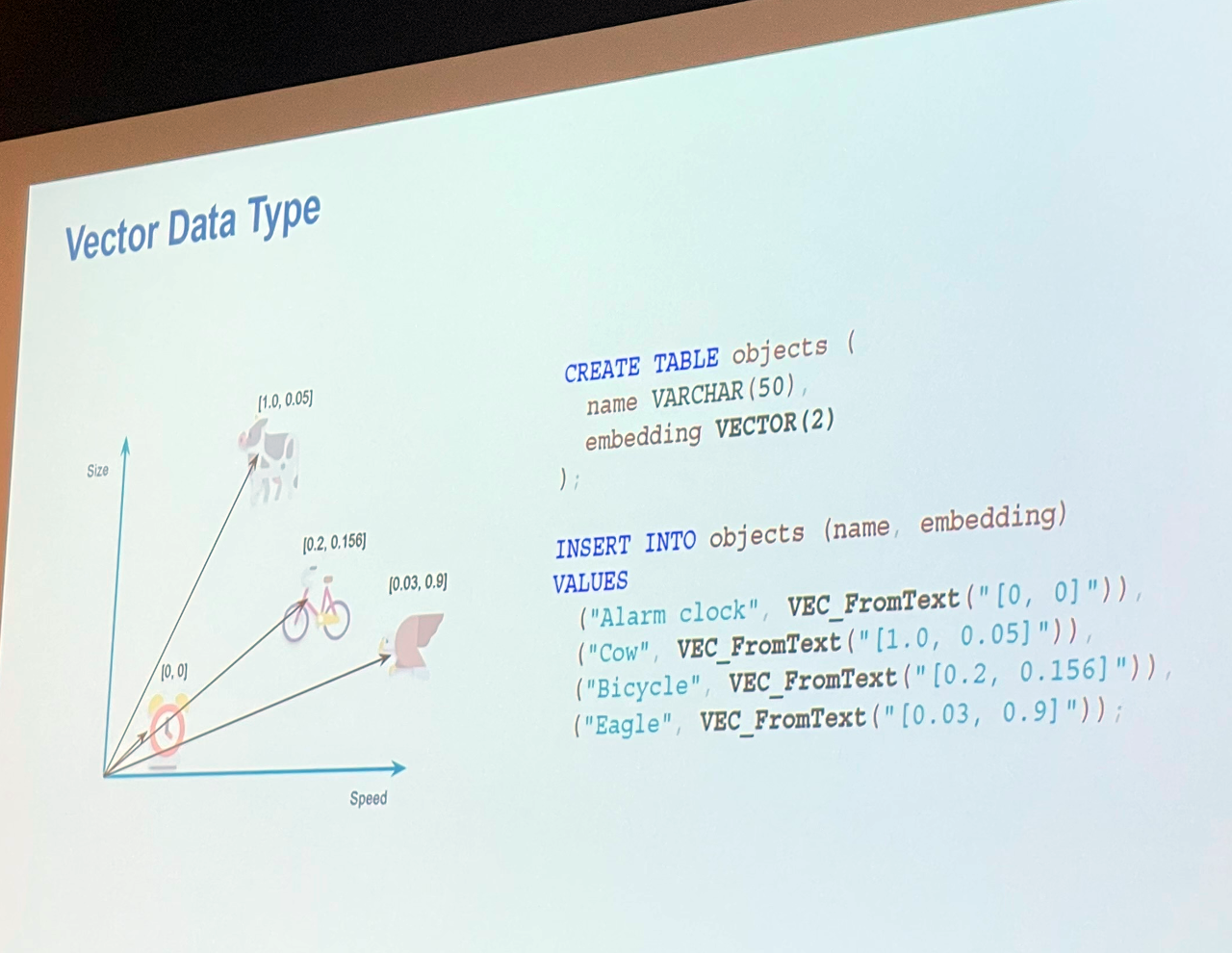
- alarm clock: small, and slow
- cow: large, and somewhat slow
- bicycle: somewhat large, and somewhat fast
- eagle: somewhat small, and fast
Then he demonstrated doing a best match lookup for a test vector (the inference portion of a model).
He choose an ant, which is small and slow, and the database returned the alarm clock. He then did a horse, and the database returned the cow.
So not perfect, but a horse is much closer to a cow than an ant to an alarm clock. More dimensions and a larger training set would go a long way toward improving the results, but I really like how his example demonstrated how the feature worked.
The second half of the presentation was on performance benchmark data showing how the MariaDB vector store compared to other options. It is surprisingly fast, to the point that even the folks on the project seemed surprised.
It would be interesting to see an independent third party test these databases. For example, the MariaDB vector store was demonstrably faster than PostgreSQL’s pg_vector, but then the test was run by MariaDB experts and not PostgreSQL experts. The PostgreSQL database was installed using defaults and may not have been tuned for highest performance. The same issues apply to the other databases in the comparison.
Still, it was impressive to see these results and it made the case that people with a need for vector storage should consider using MariaDB.

The final presentation was by Stas Bogachinsky on how MariaDB is made highly available on Amazon RDS.
Now since my three readers are pretty astute, at least one of them is thinking “hey, isn’t this the same as a sales pitch?” It could have been and parts of it were but the difference is that Stas discussed how RDS implemented various solutions that could be applied outside of Amazon.
For example, to backup a database one needs both the storage (where the data lives) and the binary logs (how the data was changed). You can snapshot the storage volumes periodically and copy the logs to other storage (S3 in the case of RDS). He also talked about replication as well as inherent limitations such as lag.
After the talks we ate pizza and socialized, which is my favorite part of such meetings. I am not sure who placed the orders for the pizzas but there were several “Hawaiian” ones (ham and pineapple). There does seem to be an almost religious fervor around whether or not fruit belongs on pizza, but I happen to like it and they did all get eaten.
As we were leaving I noticed that Monty was carrying two large plastic bags and a small “roll aboard” case. He had stopped by Forbidden Planet and loaded up on over 14kg of comic books. I thought that was cool.
I want to thank Anna for suggesting we do this and especially Azam for doing a lot of the heavy lifting. I think it turned out well and hope that everyone who was able to attend enjoyed it.