Not to misquote the Beatles, but it was 20 years ago today that I posted my first entry to this blog.
By 2003 blogs were pretty popular so I was somewhat late to the game. My friend Ben Reed had a blog that he used kind of like a proto-Twitter where he would post many times during the day on what he was doing, which at the time focused on porting KDE to MacOS. Back then a lot of open source projects used blogs as a communication platform and since I was maintaining an open source project I figured I should start one. He used Moveable Type as his blogging software so I did as well.
Moveable Type was very popular back then, but when they started to move their licensing to a more proprietary model, people were turned off and migrated to WordPress. I find it delightfully ironic that WordPress, which is open source, now forms the basis for around 40% of all websites whereas people have probably never heard of Moveable Type these days.
If there happen to be any younger readers here, blogs twenty years ago were like podcasts today: practically everyone had one. Also like podcasts, most were sporadically updated, which is why Really Simple Syndication (RSS) became important. RSS is a protocol that lets you find out when websites are updated. Using a “news reader” like Google Reader, you could aggregate all the websites you were interested in following into one application. It was pretty cool.
But then along came social media sites and what people used to post on blogs they started posting there instead of on their own sites. Even with a lot of hosting options, running a blog is incrementally harder than posting to, say, Facebook. In 2013 Google killed Reader which pretty much ended blogging (although I still use RSS and find that the open source Nextcloud News is a great Reader replacement).
But I’m old and stubborn so I kept blogging. In fact I think I have something like five or six blogs that I update periodically. I use another blogging technology called a “planet” to aggregate all of those blogs so my three readers can easily keep up with what I’m doing.
Another thing that social media brought about was this idea of engagement. People still look at metrics such as number of followers as an indication of how far a particular post reached, and even when I started this thing folks would brag about their stats. As a contrarian I took the opposite approach and decided that I’d be happy if just three people read my posts. I got a chuckle the first time someone came up to me and said “hey, I’m one of your three readers”. Made the whole thing much more personal.
And to me blogging is personal. I love to write and the best way to become a better writer is to do it. A lot. I really wish I had more time to post but between my job (which involves a lot of writing) and the farm it is hard to find the time. As someone who loves the culture around open source software, sharing is key and I hope some of the stuff I’ve posted here has helped someone else as so many other blogs have helped me.
That’s about it for this update. I would promise that I’ll post more often and with better content in the future but I don’t like to lie (grin), and in any case thanks for reading.
While I love living “out in the country” I often envy my urban friends for their network connectivity. When I moved out to the farm in 1999 the only “high speed” access was satellite, and even that required a modem and a phone line. I was overjoyed when Embarq finally deployed DSL to my house, and while 5bps down might not seem like much these days it seemed heaven-sent back then.
Jump forward 20 years and Embarq became Centurylink which is now Brightspeed. I had a pretty poor opinion of Centurylink (or as I called them CenturyStink) but high hopes for Brightspeed when they bought Centurylink’s ILEC business in our area, but they have been disappointing. Here is that story.
Both my wife and I work from home, and when our DSL circuit is working it works well enough for us to get our jobs done. At 11Mps down and 640kbps up it doesn’t even qualify as “broadband” but it is a trade off I’m willing to make in order to live where I live.
Starting back in early November we began to have issues with the quality of the DSL connection. Quality issues are always frustrating since the support technicians at the provider never seem to have the tools to properly measure it. Instead they just tell me the circuit is “up” so I should be satisfied, even though I tell them that while it is up, it is unusable.
The issue was high latency and packet loss. Latency is a measure of the time it takes information to travel through the network and packet loss indicates that some of that information never makes it to its destination. The protocols used in networking will automatically deal with packet loss by sending the information again, but the more this happens the worse the experience is for the user. Things that can handle packet loss gracefully like e-mail, web pages and chat just seem very slow, while anything that requires a more steady flow of information like video or gaming just don’t work at all.
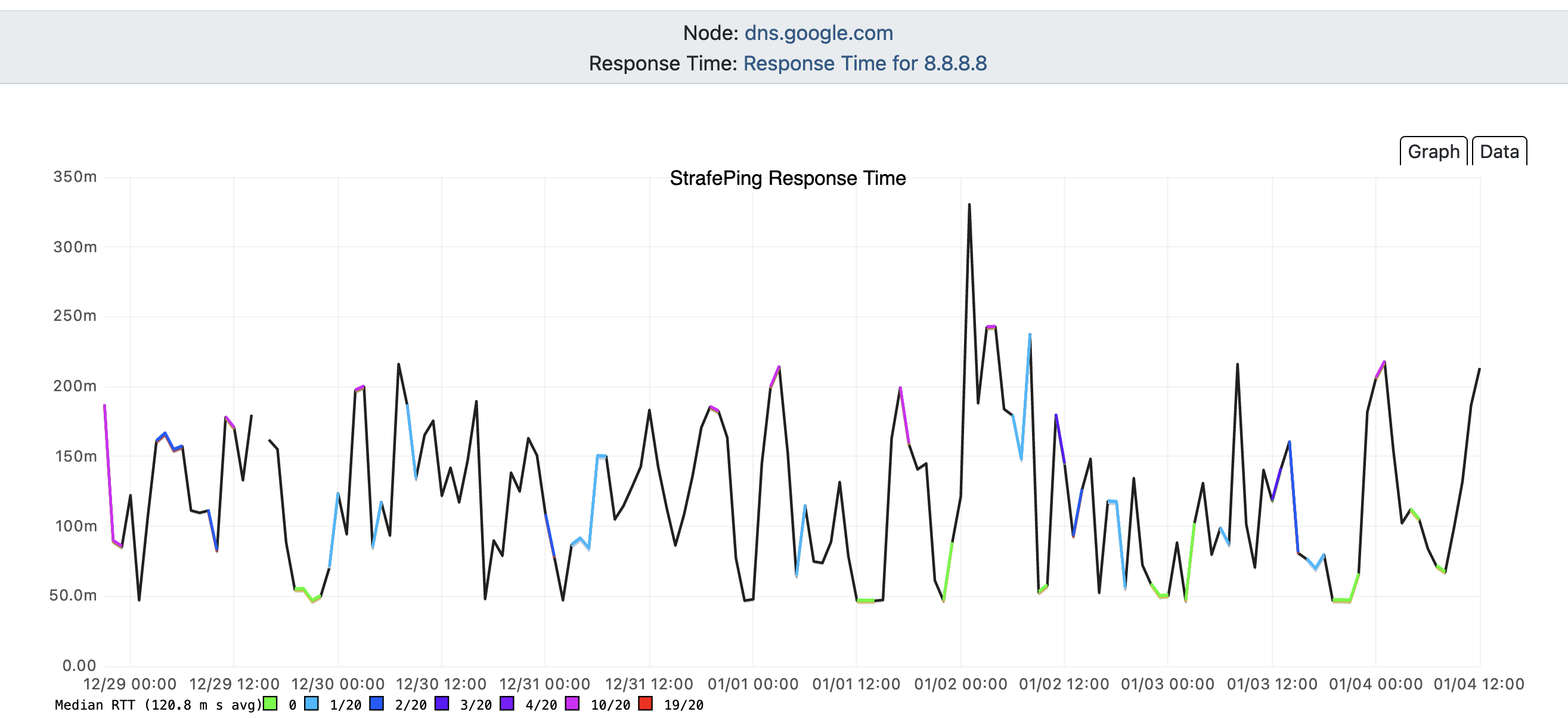
Having done network monitoring for much of my professional life, I monitor the quality of my DSL circuit by attempting to reach the 8.8.8.8 IP address, which is a highly available DNS server run by Google. Here is a recent graph:
Now normally the graph should be green and pretty much focused around 45ms. This one was all over the place. I asked my neighbor to execute a ping to the same IP address and her connection was working fine, so I assumed it was an issue specific to me.
Trying to get support from Brightspeed was very frustrating. As I mentioned above they just tend to tell me everything is okay. I even reached out to one of my LinkedIn contacts who is an executive vice president at Brightspeed for help, and I think he was responsible for a ticket being opened on November 7th in the “BRSPD Customer Advocacy (Execs)” queue. I really appreciated the effort but it didn’t help with getting my issue resolved.
Just after Thanksgiving I called again and I was told that the problem was that my modem was wrong and doesn’t work with the DSL circuit we have, even though it was the model they sent to me and it had been working fine up until November. In any case they said they would send me a replacement and it would arrive in two days.
Ten days later I call back and ask, hey, where is my modem? They told me it was still “in process” but since I’ve been waiting so long they’ll overnight one to me. It shows up the next day and of course doesn’t fix the issue, but it has newer software than my other modem and reports the status of the DSL circuit. On the web page of the device this is usually represented by the word POOR in dark red, but sometimes it would improve to MARGINAL in a slightly lighter red. I call and explain this to Brightspeed, and after dealing with this for over two months they agree to send out a technician in two days.
When I finally get the e-mail confirming the appointment, it is for the following Thursday, January 5th, eight days away. That also happens to be when we are closing on a new house, so I can’t be here to meet with them. For some appointments they show up early, so I didn’t change it right away, but when they hadn’t shown up by Tuesday I decided to reschedule it.
I went to the e-mail and clicked on the link to reschedule and got sent to the Centurylink site. Of course they wanted me to confirm my account, but nothing I typed in: phone number, e-mail, or account number, worked because I no longer have a Centurylink account. (sigh)
[Note: it looks like this has been corrected, finally, on the Brightspeed website. Not sure about links in e-mails]
In the process I did find out that my Brightspeed account number ends in “666” so perhaps that is indicative of something.
I eventually ended up calling support once again. I believe it would take the average caller about six minutes to reach a human through their system, as it prompts you for a variety of things before allowing you to speak to a person, but I had been calling for over two months so I can speedrun the thing in about four and half minutes by pressing buttons before the prompt is finished.
The person I talked to about rescheduling the appointment kept me on hold for about 30 minutes before telling me that the whole dispatch system for technicians was down and that she would call me back in two hours. She never did.
The next day I made one more attempt to reschedule the appointment, but was told that the next available appointment was so far out in the future that I should just keep it, since the technician won’t need to enter the house. I left a long letter taped next to the demarcation box on my house with a detailed description of the problem, and hoped for the best.
Unfortunately, they sent out Brandon. To my knowledge there are only two technicians assigned to our rather large county: Brandon and Elton. I much prefer working with Elton since Brandon doesn’t really seem to be the kind of person who does a deep dive into the problem, but I recently learned that Elton has moved into the back office and wasn’t doing service calls anymore.
As I feared, Brandon marked the issue as closed without fixing it. Once again into the support phone queue, where I was told that he had run a test “for five minutes” and my circuit was fine. (sigh)
I did get a text asking if my problem was resolved, to which I said “NO!” and I was later contacted by a person from Brightspeed to follow up. After a very long conversation she offered to send someone else out, and that person arrived yesterday.
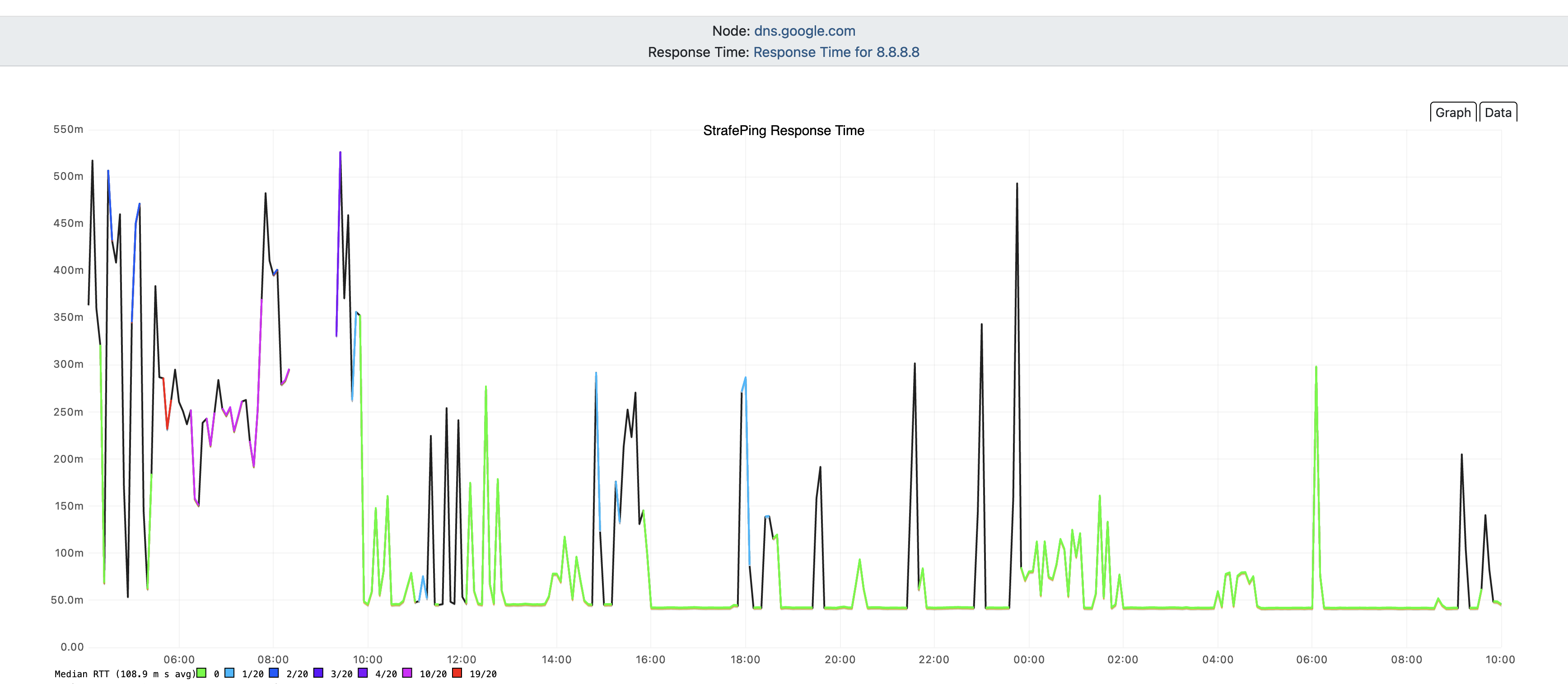
Philip, who is based out of Wake County (one county to the east of us) showed up promptly at 8am and within ten minutes had diagnosed a grounding issue with the wires coming to our house. In about 45 minutes he had repaired it, but he warned me that there was also an outage in the area which would explain my now 900ms ping times (but no packet loss). I trusted him that it would eventually resolve and about 30 minutes later things were much, much better.
You can see where the network was bad before Philip showed up, the gap where he was working on the system, and then the return to a more expected quality of service.
It still isn’t perfect. I’m seeing a lot of jitter from time to time which is indicated by the spikes, but for the most part the user experience is fine. I was able to participate in our departmental weekly video call without issue yesterday for the first time in months.
And that’s was really bothers me the most. For nearly three months Brightspeed was gaslighting me that my service was fine, when, as most IT professionals would expect, it turned out to be a physical layer problem. In retrospect it makes sense since we’ve been having an especially wet winter and that would have caused the grounding issue to be amplified.
I figure I spent between 40 and 60 hours actively involved in getting this addressed, and that is time I’ll never get back.
Of course it could be worse. The local newspaper published a story about a community in Chatham County that was without service from Brightspeed for a total of 51 days. At least our connection was usable enough that it only required a few trips to the public library for access during important deadlines.
There is some good news in that same newspaper issue that some attempts are being made to help those of us in rural areas get broadband. Some of you may be thinking Starlink, but I was on their waiting list for two and a half years without getting my equipment and when they pushed it out to late 2023 I just gave up and asked for my deposit back.
I am not a huge “we need to regulate everything” kind of guy, but broadband has become one of those services that is so important and that the free market has failed to provide that I would welcome government involvement in getting this issue addressed. But so far the communications lobby has been strong enough to prevent any kind of oversight, so I won’t hold my breath.
Ever since my parents got older, I’ve be wanting to create a tech company focused solely on making technology available for the elderly in a fashion that is easier for them to understand. Perhaps this will all go away with AI and digital assistants, or when my generation that grew up with tech gets older, but I have watched them struggle sometimes with mobile phones and TV remotes, even ones that are supposed to be simple, and I realize there is probably a market for such solutions.
While I don’t have capital for such an undertaking, I do have access to open source software and hardware, and I have a device idea that shouldn’t require heroic effort to create.
Remember the “Easy Button” from Staples?
Staples Easy Button
What I want is something about the same size, but when you press it, it will send a notice to an app on my phone.
My mother died last year and we recently bought a new home in part because it has a basement apartment where my father can live. He will have his own space but we’ll be close enough to help him out if he needs it.
The idea for this button came to me when I was thinking about what would happen if he needed some help but for whatever reason he couldn’t either call out so that we could hear him or get to a phone. Unless he was severely incapacitated he should be able to press a big button, and since I almost always have my phone with me all I would need would be an app that could send me a notice.
Since my three readers are very smart (and not to mention devilishly attractive) you have probably thought about existing services (remember the “I’ve fallen and I can’t get up” Life Call ad from 15 years ago?) but older people can be extremely proud and they hate being reminded of their age. I’m pretty certain my father would resist carrying around a device on a lanyard but he wouldn’t mind having a button nearby “just in case”.
The feature set would be pretty short:
A big button (‘natch)
Some indication that the button has been pressed (light or buzzer)
Settings:
A way to name the button
Configure the Wi-Fi connection
Configure a list of users to contact when the button is pressed
For ease of use the first generation of such a device would not be battery powered but if it was there would need to be a way to make sure the battery was charged.
While I have worked with Raspberry Pi boards I have not done anything with the Pi Zero, but I assume this would be a perfect application for it. The original Easy button could be repurposed for this device but there are also a ton of options on Amazon that could work as well.
A bit harder would be the app software, as I am lead to believe getting notices in the background on mobile devices can be tricky and I don’t want to have to have the app running all the time. I have enough skills that I could make something that would send an e-mail (which would remove the need for a separate app) but I’m hoping for a solution with more reliability and less latency. It would be nice to have it send a notice no matter where I am but if it were easier to only work when my phone was on the same local network as the button that would be acceptable (I’m trying to figure out a solution that wouldn’t involve a server).
Anyway, just putting this down as a placeholder for when I have some free time to pursue it, but I also figure someone may have done this already and by posting this I’ll find out about it.
I am always optimistic with the New Year, but 2023 has already brought me one disappointment: the death of the Dark Sky weather app.
My friend Ben introduced me to Dark Sky many years ago. Unlike most weather apps, Dark Sky focused on micro-forecasts. It would tell you when rain was imminent, how strong it would be, and how long it would last. It was amazingly useful. When I was at Lollapalooza back in 2017 a torrential downpour hit Chicago – so strong that it shut the festival down. But I remained relatively dry because Dark Sky warned me it was coming with about a 10 minute lead time. That allowed me to run to the subway and get out of the weather before the skies opened up.
In 2020, Apple bought Dark Sky and as of yesterday the Dark Sky app no longer works. The functionality has been added, or shall I say buried, within the default Apple weather app.
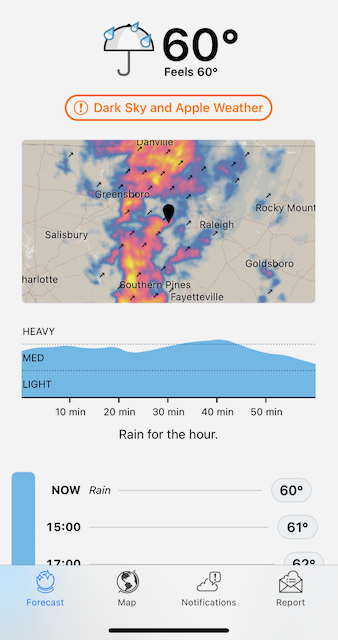
For a company like Apple that prides itself on UI/UX you would think they would do a better job of it. This is a screenshot of the Dark Sky app just before midnight on the last day of 2022.
With one click you see the current temperature, the rain outlook, and a timeline for how long the rain will last.
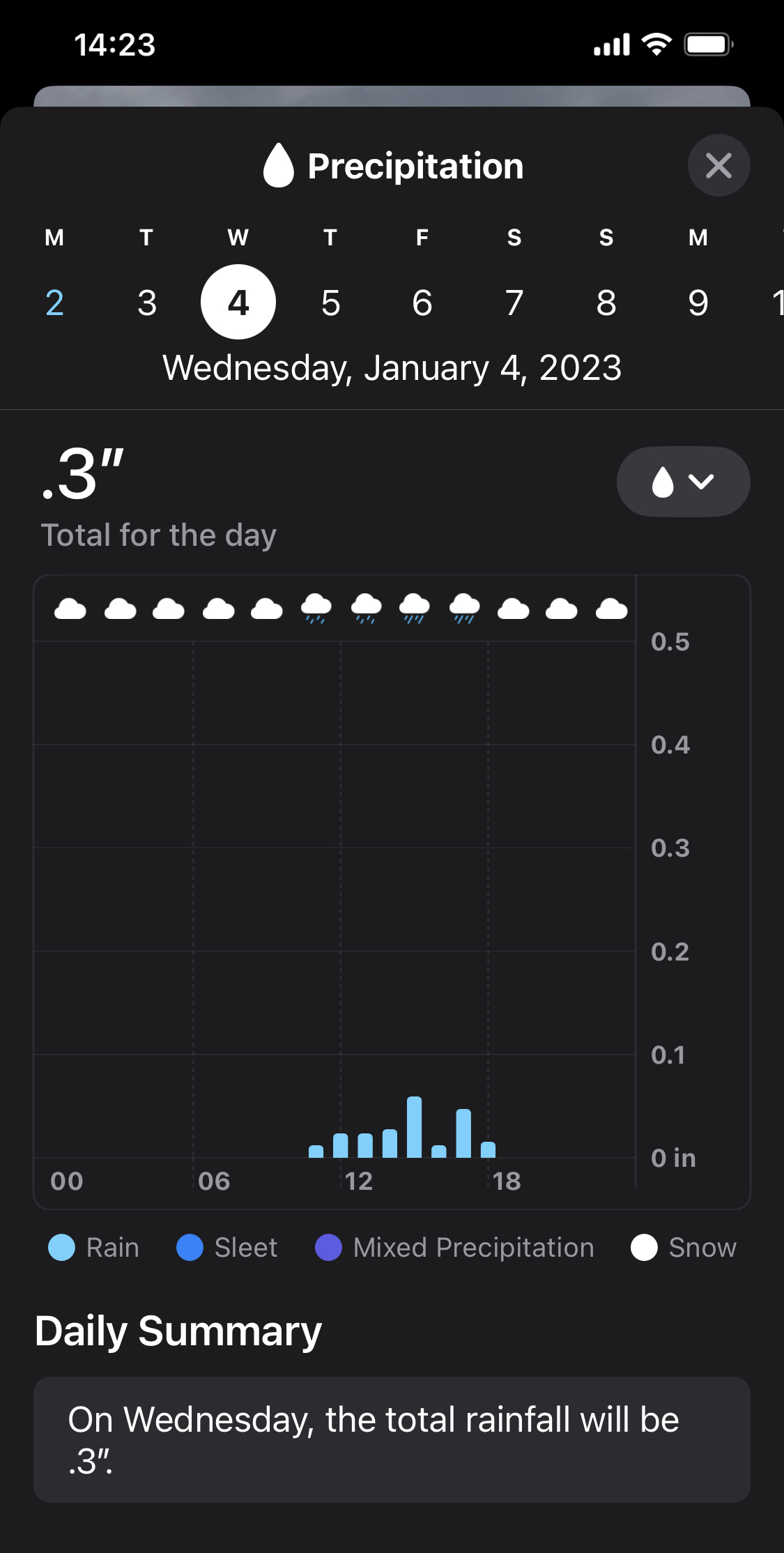
In the Apple Weather app you have to open it, scroll down until you find the precipitation widget (and not the precipitation map), click on that and you can kind of figure out the rain forecast if you look hard enough. Here is the prediction for Wednesday.
I mean, I’ll get used to it, but it is sometimes hard to say goodbye to something you’ve used for years. If the app were open source there is a chance it would live on, but when we opt to use proprietary software we also cede a lot of choices to the software vendor. So it goes.
The thing I like most about my job is that I get to meet and work with amazing people. Recently I traveled to Helsinki, Finland, to attend the MariaDB Server Fest conference. It was a great experience and I met some very talented people, including Monty Widenius himself.
Note: The usual disclaimer that this is my personal blog and what I write here does not necessarily reflect the views of my employer, Amazon Web Services
My role at AWS is to work with open source companies and communities and to act as a liaison between them and Amazon. In thinking about important open source projects one of the first that comes to mind is MariaDB.
When I first got seriously involved in open source back in 2001, the MySQL database was an example of an open source success story. While a lot of the focus of the early days of open source was on the operating system, MySQL demonstrated that open source applications were powerful enough to compete with existing proprietary solutions. Plus, if you were building an open source application, quite often you needed a database, and MySQL provided a great option.
Many of us expected MySQL to IPO, but instead the company was bought by Sun Microsystems. That wasn’t too worrisome since Sun was a big proponent of open source, but when Sun was bought out by Oracle a couple of years later, that all changed.
On the day the acquisition was announced, Monty Widenius (the lead developer of MySQL) announced a fork of MySQL called MariaDB. In the years since then, a lot of people have replaced MySQL with MariaDB. While Oracle has continued to work on MySQL, the last major release, version 8.0, came out in April of 2018 so one must wonder how motivated they are to work on a product that competes with their main proprietary offering.
When I learned about Server Fest I decided to attend. As much as I like the ease of remote communication, sometimes nothing beats meeting face to face. I had also been to Helsinki a couple of time before and I really like the city, although I really should try to visit once in the summer time.
Boarding Sign for Flight to Helsinki
I flew from North Carolina to JFK and then took a Finnair flight to Finland. Helsinki is seven hours ahead of New York, so it is one of those weird trips where you leave in the night and land the following afternoon. When I travel I tend to stay at Marriott properties, but all the Marriott affiliated hotels were booked. I later learned that this was because a popular start-up conference called Slush was happening at the same time as Server Fest. Because of this there was no meeting space for rent, so the MariaDB event was being held at Monty’s house, which I thought was kind of cool.
Proposed schedule for Server Fest 2022
The conference was on Thursday, November 17th, and was going to be live-streamed on YouTube. In order to better match up with the time zone in New York, it started around 3pm and ran into the night. I arrived mid-morning.
When you walk into Monty’s house, the first thing you notice is that is has a very open floorplan. Directly across from the entryway is a huge table that can probably seat about 20 people, and that’s where most folks had set up their laptops. To the right of that was a large kitchen, and to the left was an open area where the walls were lined with bookcases, and that is where lights and cameras had been set up for the livestream.
Now MariaDB is organized in two parts. There is the MariaDB corporation, which is the main commercial enterprise behind the project, and there is the MariaDB Foundation, which manages project governance and promotion. Both were represented in the day’s presenters, and I also got to meet and spend a lot of time with Kaj Arnö, who is the CEO of the Foundation.
I also got to meet the true boss of the event, Anna Widenius, Monty’s wife. As you can imagine, getting a bunch of open source geeks organized is like herding cats, but she did a great job in getting the conference underway and keeping it moving.
He talked about “Chasing Bugs in Production”. When Wikimedia upgraded from MariaDB 10.4 to 10.6 they ran into a performance issue. His talk describes their upgrade process and how they were able to work with MariaDB to get the issue addressed. I also found it interesting that they run MariaDB on bare metal. So much of today’s IT infrastructure is based on clouds and Kubernetes that it was refreshing to see someone taking advantage of individual servers when it makes sense.
There was a bit of a hiccup with the second speaker who was supposed to join remotely, so Monty Widenius moved his presentation on query optimization in MariaDB to the second slot.
Monty Widenius Presenting
There are several methods that can be used to execute a query against a database. A good database will optimize the query method to choose the best plan to return the result in fastest time. In MariaDB 11, Monty has changed the method to use a cost-based optimizer (versus rule-based) with parameters that can be tuned by the user. This has resulted in more efficient queries and thus a better user experience.
His topic involved the community, and I really liked his comment that MariaDB is “dependent on its users to give MariaDB its purpose” which I thought was pretty insightful.
MindsDB allows you to integrate machine learning easily into your database. In his example he used a model trained by Hugging Face to analyze text in order to detect “sentiment” – i.e. is the text positive, negative or neutral. And you access this using SQL queries.
For example, supposed you have a blog or other website where users can submit comments. MindsDB would allow you to examine those comments to detect general sentiment without having to learn an entirely new system. I thought it was pretty cool.
This resonated with me as it focused on building the sponsorship community within MariaDB, for both individuals and entities. MariaDB is an important piece of technology and there are a lot of stakeholders, and this talk really reinforced the idea of a “big tent” environment within the project.
For the next presentation we finally got to hear from Federico Razzoli founder of Vettabase (he was originally scheduled to go second but there was some time zone confusion) as he talked about new MariaDB features to learn “for a happy life”.
Federico Razzoli via Zoom with Kaj Arnö
He started off with the comment that MariaDB (and open source projects in general) are very good at creating new features and not so good about documenting or advertising them. He discussed the most recent releases of MariaDB and then highlighted various new features that people should find useful.
The seventh presentation was by Sergey Petrunia and revisited the optimizer, but focused on changes made before Monty’s changes in MariaDB 11.
Sergey Petrunia Presenting
His talk focused on those changes made in the last year (i.e. since the last Server Fest) and it looks like a lot of progress was made to make the optimizer more consistent.
From what I can tell, the idea behind MVCC is that active databases are constantly processing transactions but there is a need to provide a consistent “view” at a given point in time, so MVCC determines which transactions are supposed to be considered committed at that point in time and which are not. This is to prevent someone who is reading from the database from being served incomplete information.
As transparency is key to any open source project, MariaDB publishes statistics on code contributions. The latest one I can find is through September of this year, and I was happy to see Amazon on the list of contributors to the MariaDB Server code.
Of course the majority of code commits, nearly 80% were done by the MariaDB corporation, and another 14% by the MariaDB Foundation. Amazon represented 1.42% of contributions, but Andrew pointed out to me that they came from 14 unique committers versus 8 from the Foundation. I’d love to see that involvement increase.
The mariadb-binlog is a binary log containing a record of all changes to the databases, both data and structure. There is a command line tool that lets you examine this log which now supports Global Transaction IDs, making it easier to filter transactions.
After the Server Fest stream was over, we got to my favorite part of any conference – the socializing.
I did spend some time talking with Manuel Arostegui. One of my friends, Eric Evans, works at the Wikimedia Foundation focused on Cassandra. It turns out that both Manuel and Eric are in the same department. Small world.
Manuel and Me
We eventually sat down to dinner prepared by the Widenius’s. Monty cooked a huge beef tenderloin, and we talked, sang songs and drank. I managed to get back to my hotel about 1am the next morning.
Usually when I travel home from Europe my flight will leave around noon and I get back in the early afternoon local time. For some reason those flights were over $1000 more than the Finnair flight that left at 5pm, so I returned to Monty’s on Friday morning to visit for a few hours.
I loved the fact that Monty was so welcoming and also that he and his family keep a lot of animals (we do the same). In addition to six cats and three dogs, there is a boa constrictor named Monty Python who is about two meters long. The story I heard was that it was a gift given to a family member that ended up at Monty’s. They originally thought it was a python but later learned it was a boa, but the name stuck.
Monty Python the Boa Constrictor
The trip home was uneventful except for the fact that I got home home close to 2am and I ended up catching a bad case of influenza. To my knowledge no one else at the conference got sick, for which I’m happy, and while it knocked me out of commission for almost two weeks it was worth it.
Today marks my three month anniversary with AWS, and I’m loving it. It has been a lot of fun returning to conferences, so I thought I’d post a list of the ones I will be attending for the rest of the year.
The last day of SCaLE was bittersweet, as I didn’t want it to be over but I was also ready to head home.
After stopping by the booth I was eager to visit a session on OpenNMS presented by my friend Jeff Gehlbach.
Jeff has stepped up in the the presenter role I used to have, and he did a very good job of covering what network flows are, the different types and why they are important.
Back in the Exhibit Hall I was happy to learn that the AWS booth had won the “Most Memorable” award.
Hats off to Spot and Ashley for coming up with such a cool concept and creating a great space for people to hang out.
At 1:30pm we held a raffle for a pretty nice 3D printer. You had to be present to win and there was a lot of interest.
Then it was time to tear down the booth as the Exhibit Hall closed at 2pm.
This gave us time to get to the closing keynote by Internet pioneer Vint Cerf.
For someone who recently turned 79 he was a dynamic and entertaining speaker, and it was fun to listen to his stories on creating ARPANET, and how it grew into the public Internet we use today.
He also mentioned Jon Postel several times. I had an e-mail correspondence with Jon in the mid-1990s when I was trying to wrap my brain around the process for getting an “enterprise number” from IANA. I didn’t realize until after his untimely death who he was, and I’m still impressed at how much time he was willing to give a newbie like me.
While I enjoyed the presentation, I did regret that we ran out of time for details on his last slide, which concerned “unfinished business”.
I mean, I get it. Each of the six topics on the slide could be a talk on its own, but I was very curious to hear his thoughts on fixing things such as disinformation. I love living in a world with almost instant access to information and the ability to connect with others, but there are problems, too, and I’m not sure we have the solutions.
All in all I am extremely happy to have been able to attend SCaLE. I’m still not comfortable in crowds and I was a little put out that not everyone in attendance decided to honor the mask policy. I talked with the SCaLE staff and they told me they were doing all they could, but even when people were reminded to mask up they tended to remove them as soon as the staff member walked away.
I was especially unhappy when I saw sponsors going maskless. On the one hand I am happy for their support of SCaLE, but on the other when you are standing in front of your company logo showing a disregard for the safety of your potential customers, it sends a bad message.
I’m not bringing this up to start a debate on the efficacy of masks, as I realize that they provide varying degrees of protection depending on type and use, but if your staff isn’t willing to abide by the conference rules, perhaps you just shouldn’t be there.
Note that I did refrain from posting the pictures I took of specific sponsors since it really wouldn’t change anything. I must be getting soft in my old age.
In any case I hope this is a non-issue for SCaLE 20x in Pasadena next March. I’m not optimistic that the pandemic will be over but for me the risk was worth the benefit, and I can’t wait to return.
Day Three of SCaLE kicked off the start of the main conference, which meant I spent most of the day in the AWS booth.
Traffic was pretty good and I got to talk with a lot of interesting people. I did take a break around 2pm and noticed from Twitter that I was missing a talk by Frank Karlitschek of Nextcloud fame, so I skedaddled over to his room to catch it.
It was pretty good. It focused on how copyleft-style licenses are often better for business since they level the playing field for all contributors, versus a number of newer licenses that are more “source available” instead of “open source”.
Please note that I’m an unabashed Nextcloud fanboy so I have some biases. (grin)
The big evening event was “Game Night” where they turned the basement ballrooms into a big gaming playground. From the classics such as checkers and chess, to Vegas-style games such as roulette and blackjack, up to the most modern of games using VR, there was something for everyone.
AWS sponsored the music for the event, and I was eager to see MC Frontalot perform. He didn’t disappoint.
He did an hour-long set spanning the classics to the newer stuff, including “Secrets From the Future” featuring a video generated using AI.
Afterward he hung out at the merch table to chat with folks, and I got to spend some time with a new friend named Silona Bonewald.
I was introduced to Silona through Spot as she was on the same hotel shuttle bus when we arrived on Wednesday evening. She is in charge of open source at IEEE as well as being a Burner, and I always look forward to chance to talk with her.
Today is the final day of the conference, and remember if you are reading this before 1:30pm PDT there is a raffle for an awesome 3D printer at the AWS booth, so come by to get your ticket.
This is the first conference since joining AWS that I have booth duty, so I won’t be able to spend as much time in the sessions as I would like, but I did want to catch one of the first sessions of the day which was “Speedrunning Kubernetes”.
The main reason I wanted to see this talk was to see Kat Cosgrove in action. Prior to coming to AWS I didn’t know about her but I ended up following her on Twitter and found that she has strong opinions, and I tend to like people who have strong opinions. I figured the presentation would be entertaining and that I might learn something.
I wasn’t disappointed.
The title alludes to a “speedrun” which is an attempt to complete a video game as quickly as possible. The goal of this talk was to bring up a working Kubernetes cluster as if you were doing a speedrun. It also included one of the more … unusual … analogies I’ve seen in a technical presentation (including my own) by using a Chihuahua as a metaphor.
If the goal is to provide the “cheeseburger” application, consisting of the bun service, the patty service, the cheese service, the mustard service, etc., each instance of the application (i.e. each burger) can be considered a “pod”. There are two pods under each foot of the dog representing two-pod “nodes” and the dog forms the control plane.
Remember, now that you’ve seen it, you can’t unsee it.
That was the only session I made on Day Two, but I did get some time to wander around the Exhibit Hall. The Software Freedom Conservancy had a booth, and since they are one of my favorite organizations I stopped by to chat with Pono Takamori. I know a number of folks that work there and they serve as almost a reference implementation for trying to live using 100% free software. Pono was telling me that it was getting almost impossible to find a totally free mobile wireless solution since 3G went away, as all of the modern modems tend to use binary blobs.
Now, when these exhibit halls are being set up, the “booths” are laid out with little generic signs showing the owner of the booth, and most of the time they eventually get covered up once the booth is complete.
I know the Sun acquisition was a long time ago, but I still get cognitive dissonance when I see a MySQL sign next to an Oracle one.
The AWS booth for this conference is really awesome. I bow down to the genius that is Spot Callaway, and he pitched a booth design that was to invoke a teenage geek’s basement, where one might play video games and Dungeons and Dragons (think Stranger Things). The walls of the booth are made to look like brick, and there are chairs, a couch and an SNES console emulator.
The featured AWS project for this conference is Bottlerocket, and I got to learn a bit about it and meet members of the team. Bottlerocket is a minimal operating system designed just to run containers. I compared it to LibreELEC, which is a purpose-built O/S that I use to run Kodi, and while it was explained to me that I was oversimplifying things a bit, it was otherwise a good analogy.
While it is, of course, being used withing AWS, it is a 100% open source project and you can get the code on Github, and the hope is that others will find it valuable and will get involved with the community. If this is something you’re into, stop by the booth and say “hi”.
Speaking of stopping by the booth, we do have some tasty sodas and Bottlerocket branded bottle openers, but the big giveaway is an awesome 3D printer. Get a raffle ticket and stop by the booth at 1:30pm on Sunday for the drawing (you must be present to win).
AWS employees are not eligible to participate. (sniff)
I am back at the Southern California Linux Expo (SCaLE) for the first time in many years, and I was surprised at how happy this makes me. It is always a well run conference and it tends to bring a lot of people I like together in one place, which means I get to meet a lot more people to like as well.
The main SCaLE sessions occur over the weekend, but there are a lot of cool things that happen in the days before. For Thursday, AWS sponsored Cloud Native Builder Day to showcase some of the amazing open source technologies one can use to solve a number of challenges, and I was eager to learn about them.
But before that I needed to get registered. The first step was to show proof of vaccination. While I am thankful that we can have these events, COVID is still a thing and the organizers are doing all they can to mitigate the risk to the conference attendees. Since I’m an old I’ve had two shots and two boosters but the darn thing keeps mutating.
Once past that I headed upstairs where I could use the self check-in kiosks. It was pretty simple to sign in and get my badge printed, and then it was just a short trip down the hall to pick up the conference “swag bag” which included the badge holder and lanyard.
The only change I would make to the process is that once you printed your badge, you should really hit the “close window” button on the screen, as there is a “back” button that could allow the next person who registers to see your name and e-mail. No biggie, but the security nerd in me always thinks about these things.
The conference spans two floors. The Exhibit Hall with the sponsor booths is on the ground floor behind registration (it is technically in the Plaza Ballroom so I just followed the signs for “ballrooms”) while the sessions are on the second floor along with registration. AWS is going to have a pretty cool booth this year.
As an AWS employee I guess I should say that we always have a cool booth (grin) but I especially like the idea behind this one, despite the fact that we were unable to get a mounted deer head (seriously). It’s booth numbers 300, 302 and 304 if you want to swing by, and for those of you who couldn’t make it I’ll be sure to post about it later.
Cloud Native Builder Day showcased three different open source projects, the first one being Triggermesh. This was presented by Jeff Naef who I immediately liked as he was the first to notice that my mask is made by K&N, a company known for their high-end automotive airflow products. He loves performance automobiles as well as open source (he was wearing a Snap-On tools hat) so I knew we would get along.
In dealing with cloud native technologies, a lot of the workflow is event driven. Triggermesh lets you seamlessly link together sources and targets for events, normalizing and enriching them along the way. While it does support the ability to create functions using code (in a variety of languages) a lot of the implementation can be done just through configuration.
In one example the data was encoded in base64, and a person asked if Triggermesh could render that in clear text. Jeff was like, sure, and he bravely set out to implement that as we watched. He got really close, but in any case deserves kudos for the attempt, especially considering he was holding a microphone with one hand the entire time.
The next speaker was Zoe Steinkamp from InfluxDB. I first met Zoe at the Open Source Summit in Austin and she is one of my favorite new acquaintances I’ve met through my job at AWS.
Now full disclosure: I missed the first half of her presentation.
SCaLE has done something delightful with the schedule, which is allowing 30 minutes between talks. I’ve talked about this before but this lets speakers switch out without the usual urgency, allows more time for attendees to interact with the speaker after the talk, and improves the hallway track.
I thought I had enough time to grab lunch, which was In-N-Out that Spot had brought for me. We don’t have In-N-Out in North Carolina so I rarely pass up a chance to get it, and I figured I could be back in time. I was wrong. But I did slip into the back of the room which is why this picture isn’t as close as the others.
I used to work on an open source project that relied heavily on time series data, so I’m a bit of a time series data geek. Every time I see a presentation on InfluxDB I learn more things to like about it. This time I found out that it is possible to get started with it without being a programmer. A lot of people in the data science field aren’t coders, but they can send their data to InfluxDB pretty easily. The folks at Influx have created InfluxDB University as a free resource to get the most out of their solution, and while I haven’t gone through it yet it looks really comprehensive.
When most people hear the word “database” they think of relational databases. This is a data structure usually based on “rows” of data made up of “fields” and indexed by a primary key. One then uses something like the Structured Query Language (SQL) to retrieve values from those fields. This is all well and good but it tends to be extremely monolithic, which doesn’t work well in today’s distributed cloud environment.
Think about it. In a datacenter you might have sub-millisecond latency, so a query can be returned quickly. Move that datacenter across the country, and now it your latency is, say, 100ms. Move that to the other side of the world and, well, you get the picture. Now if you only have a few queries that might be okay, but when you consider thousands and then millions of queries, the response time of your application is going to take a hit.
Cassandra allows you to distribute that data both within a datacenter (for reliability) and also regionally. You can then put your data near your customers, improving their experience.
I was already sold on Cassandra (we used it at OpenNMS) but what I learned from this presentation was the wonderfulness that is “k8ssandra” (kate-sandra). This is Cassandra but running in Kubernetes. If you have ever had to extend and expand a Cassandra cluster, you know that while it isn’t super difficult there are a number of gotchas that can cause problems. What if you could automate it? Matt showed us an example that let him spin up (and tear down) an 800 node cluster in minutes.
Cool, huh?
The first day of SCaLE 19x was a blast, and I am eager to see what the rest of the week brings.